
In the modern academic landscape, the sheer volume of information generated is staggering. From longitudinal climate studies to massive genomic sequencing and social media sentiment analysis, researchers are no longer just “gathering data”—they are managing digital ecosystems. The challenge has shifted from finding enough data to effectively processing, storing, and analyzing it without compromising integrity or efficiency.
Managing large datasets requires a strategic blend of robust hardware, sophisticated software, and meticulous organizational practices. For researchers in the United States, adhering to data management plans (DMPs) mandated by federal agencies like the NSF or NIH is not just a best practice; it is a prerequisite for funding. This guide explores the essential toolkit required to turn overwhelming data into actionable academic insights.
The Pillars of Modern Data Management
Before diving into specific software, it is vital to understand the “Big Data” challenges in academia: Volume, Velocity, Variety, and Veracity. High-performance computing (HPC) and cloud-based infrastructures have become the backbone of university research departments to address these needs.
However, the technical barrier can be high. Many students and early-career researchers often find themselves overwhelmed by the complexity of cleaning and preparing data. It is common to seek professional guidance from experts at myassignmenthelp to ensure that the foundational data analysis assignment help is handled with precision. By outsourcing the more tedious aspects of data scrubbing, researchers can focus on higher-level hypothesis testing and theoretical synthesis.
1. Data Cleaning and Preparation Tools
Data is rarely “clean” when first collected. “Dirty” data—containing outliers, missing values, or inconsistent formatting—can lead to skewed results.
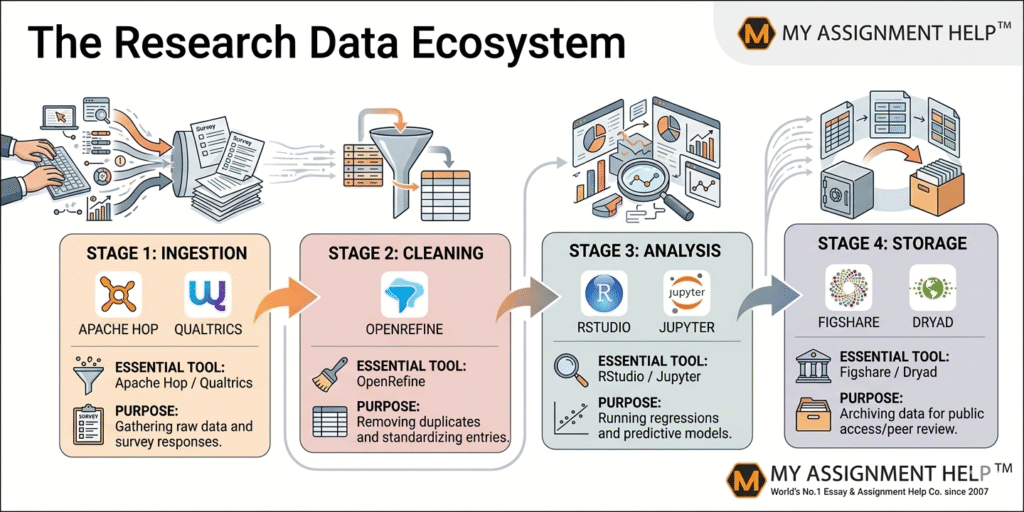
- OpenRefine: Formerly Google Refine, this is a powerful, free tool for working with messy data. It allows you to transform formats, clean up inconsistencies, and link your dataset to external datasets through reconciliation services.
- Trifacta: Known for its “wrangling” capabilities, Trifacta uses machine learning to suggest common transformations, making it ideal for researchers who may not be proficient in Python or R.
2. Statistical Analysis and Computational Software
Once the data is prepared, the heavy lifting begins. The choice of tool often depends on the discipline.
Python and R: The Dynamic Duo
Python and R remain the gold standards for data science in academia.
- Python: With libraries like Pandas for data manipulation and Scikit-learn for machine learning, Python is incredibly versatile.
- R: Specifically built for statisticians, R offers the Tidyverse ecosystem, which simplifies the process of data exploration and visualization.
SAS and SPSS
For social sciences and healthcare research, SPSS and SAS offer a more GUI-based (Graphical User Interface) approach. These tools are highly valued for their rigorous documentation and long-standing reputation for reliability in peer-reviewed publications.
3. Storage and Collaboration Platforms
Managing large datasets is rarely a solo endeavor. Collaboration requires version control and secure storage.
- OSF (Open Science Framework): A free, open-source project management tool that supports researchers throughout the entire project lifecycle. It integrates with tools like Dropbox, Google Drive, and GitHub.
- AWS for Research: Amazon Web Services provides scalable storage (S3) and computing power (EC2) that can handle petabytes of data, offering “pay-as-you-go” models that are cost-effective for university budgets.
Overcoming the Academic Hurdle
For many students, the leap from small-scale statistics to large-scale data management is daunting. When the pressure of deadlines mounts and the technical requirements of a dissertation become too complex, it is helpful to reach out for support. You can easily hire an expert to do my homework to manage these technical bottlenecks, ensuring your research remains on schedule without sacrificing quality.
Adhering to E-E-A-T Standards
In academic writing, Experience, Expertise, Authoritativeness, and Trustworthiness (E-E-A-T) are paramount. Every tool mentioned above should be used within a framework of ethical data handling. This includes ensuring data anonymity, securing informed consent for human subjects, and maintaining a transparent “audit trail” of how data was modified from its raw state to its final analyzed form.
Key Takeaways
- Plan Ahead: Always create a Data Management Plan (DMP) before starting your collection.
- Automate Cleaning: Use tools like OpenRefine to reduce human error in data entry.
- Prioritize Security: Use encrypted cloud storage for sensitive or proprietary research data.
- Seek Assistance: Don’t hesitate to use specialized services for complex data analysis or documentation.
FAQ Section
Q1: What is the best tool for a beginner in data analysis?
A: Tableau or Microsoft Power BI are excellent for beginners because they focus on visual drag-and-drop interfaces rather than complex coding.
Q2: Is Python or R better for academic research?
A: It depends on the field. R is generally preferred for pure statistics and social sciences, while Python is better for large-scale data engineering and machine learning.
Q3: How do I ensure my large dataset is “clean”?
A: Perform exploratory data analysis (EDA) first. Check for null values, verify data types (e.g., ensuring “Dates” aren’t saved as “Text”), and use histograms to identify outliers.
Q4: Where can I host my research data for public access?
A: Platforms like Zenodo, Dryad, and Figshare are designed specifically for academic data sharing and provide a DOI for your dataset.
About the Author
Dr. Sarah Jenkins
Dr. Sarah Jenkins is a Senior Research Consultant at myassignmenthelp with over 12 years of experience in quantitative research and big data analytics. Having earned her PhD from a top-tier US university, she specializes in helping doctoral candidates navigate complex statistical models and data management protocols. Sarah is a frequent contributor to journals on academic integrity and digital pedagogy.
References
- National Science Foundation (NSF). (2025). “Dissemination and Sharing of Research Results.”
- Wickham, H., & Grolemund, G. (2023). “R for Data Science.” O’Reilly Media.
- McKinney, W. (2024). “Python for Data Analysis.” O’Reilly Media.
- Association for Information Science and Technology (ASIS&T). (2026). “The Evolution of Data Management in the Digital Age.